Глубокое обучение (Deep learning)
Нейронные сети становятся глубокими, грубо говоря, когда в ней используется несколько скрытых слоев. С первого взгляда кажется, что увеличение слоев может не принести большой пользы, но на самом деле такая архитектура обладает намного большей мощностью и эффективностью по сравнению с однослойной.
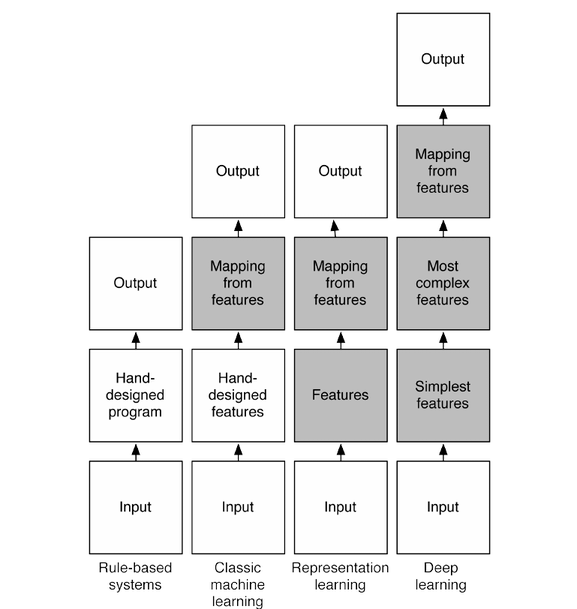
Здесь серым цветом указаны компоненты, которые самостоятельно обучаются на данных
Основная идея глубоких сетей заключается в том, что представление данных разбивается на множество абстракций. Каждый последующий слой обучается более обобщённому виду. Такая связь называется обучением представлениями.
В качестве примера можно посмотреть на следующую картинку:

Тут каждый слой отвечает за свой уровень абстракции. Первый слой отвечает за базовые части, такие как наклонные линии, кривые, углы и т.д. Далее идет комбинация этих частей в более комплексные варианты, отвечающие, например, за глаз. С каждым последующим слоем происходит абсолютно идентичная ситуация. Данные просто принимают более сложный вид.
(!! надо ли?) Parameters sharing
Почему именно сейчас?

Секреты успеха:
- Много данных
- Более 100 часов видео заливается каждую минуту на Youtube
- Социальная сеть ВКонтакте хранит огромное количество информации о пользователях (в день в ВК заходят более 80 млн.)
- Вычислительная мощность
- С каждым годом видео-карты становятся в разы мощнее
- Распределенные вычисления
- Новые алгоритмы
- Алгоритм ReLU позвлил обучать сеть точнее и намного быстрее
- Новые методы оптимизации повышающие эффективность сетей: Dropout, Batch Normalization
Успех в компьютерном зрении
В области компьютерного зрения всегда была, есть и будет одна самая главная цель - понять, что изображено на картинке. Человек ли там или дерево? Поэтому для проверки различных алгоритмов существуют соревнования по классификации изображений. Одним из таких соревнований является ImageNet Competition, в котором используется база ImageNet, состоящая из более чем 12 миллионов изображений. Всего в ней 1000 основных классов.
Главным мерилом всех этих соревнований является процент ошибки. Он бывает топ-1 или топ-5. Это означает, что мы приводим полученные алгоритмом результаты к полиномиальному распределению, где сумма вероятностей всех классов равна 1. Таким образом для каждого класса есть своя вероятность того, что на изображении находиться именно он. Соответственно, для топ-1 классификации, ответом будет класс с наибольшей вероятностью. И если этот класс не совпадает с правильным классом, то это считается за ошибку. Для топ-5 берется 5 классов с наибольшей вероятностью.

Каждый год различные алгоритмы компьютерного зрения уменьшали топ-5 процент ошибки в среднем на 2%. Но в 2012 году выиграла небольшая (по сегодняшним меркам) сверточная нейронная сеть, состоящая из 8 слоев. Только она уменьшила процент ошибки сразу на 10%. Это результат, о котором в то время даже и не думали. С тех пор и начался успех глубоких сеток, который продолжается и по сей день.
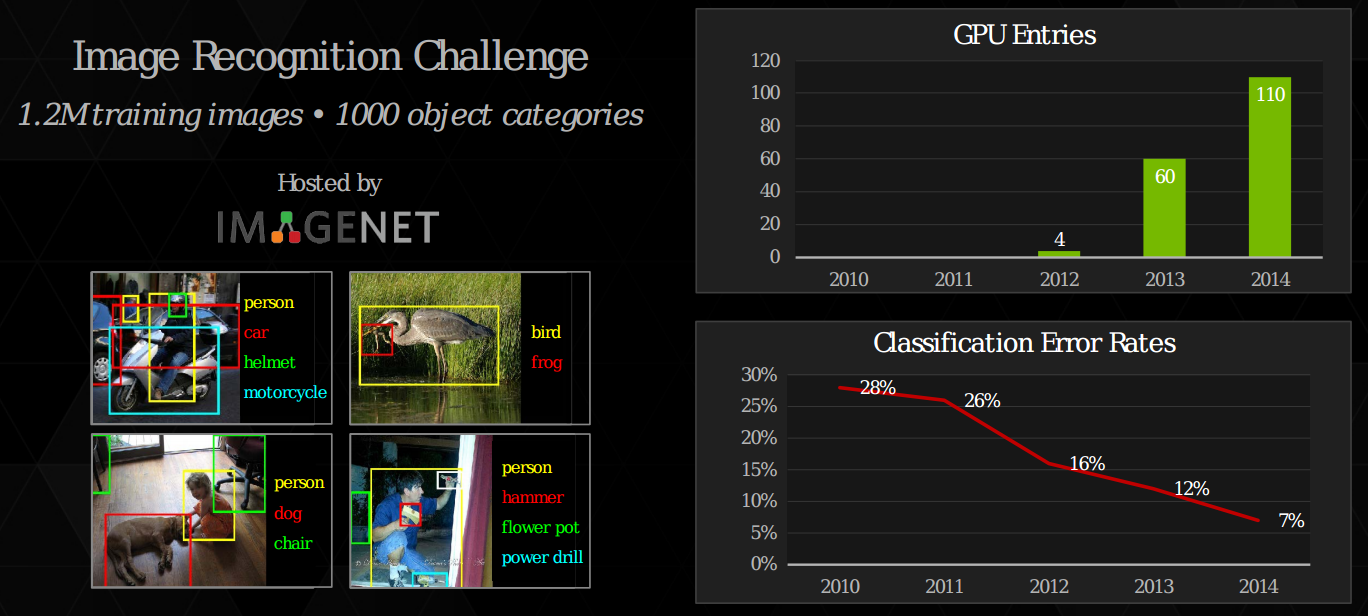
И с каждым годом количество слоев существенно увеличивается:

Как используется сейчас
Локализация различных объектов на изображении:

Описание происходящего:

Скрещивание двух изображений:

Распознавание речи человека:
