Нормализация данных
В предыдущем пункте показано, что нехорошо иметь большие "выделяющиеся" веса, потому что они сильно влияют на систему в целом. Такая же ситуация бывает и с данными. Допустим у нас есть такой набор входных данных:
| Признак | Значения |
|---|---|
| Зарплата в год | от 100.000 до 20.000.000 (разница в 100 раз) |
| Количество часов работы в неделю | от 10 до 60 (разница в 6 раз) |
Исходя из этих данных нужно предсказать какую-то ерунду.
Проблема в том, что алгоритм прямолинейно считает эти большие числа в зарплате и никак их не нормализует. Это значит, что градиентный спуск будет использовать один параметр, который меняется всего в несколько раз и другой параметр, который меняется в сто раз. А как уже было сказано, чем больше у нас "растянутость" (зависимость от одного параметра), тем сложнее сходиться будет градиентный спуск. Для того, чтобы решить эту проблему и используют некоторые техники описанные ниже.
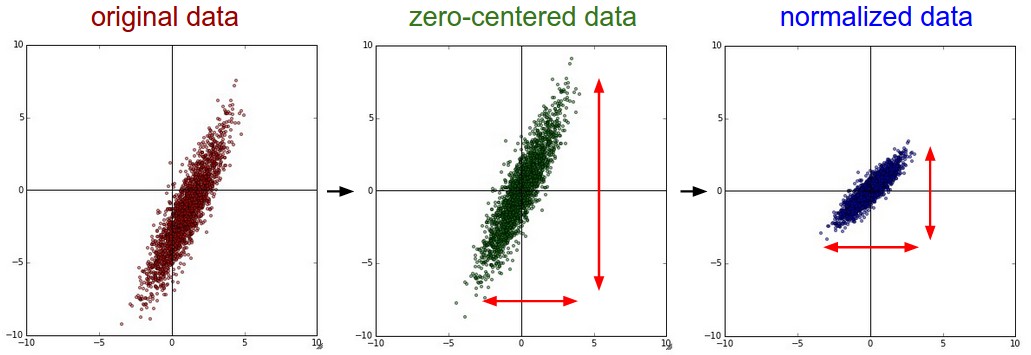
Вычитание среднего
Удобно вычислить среднее из всего набора обучающих данных чтобы потом вычесть его из остальных наборов (валидационный, тестовый). В результате у нас получаться данные распределенные вокруг центра.
Масштабирование
Здесь переменные делятся на разницу между максимумом и минимумом. Таким образом диапазон значений уменьшается до 1.