Развитие искусственных нейронных сетей
Искусственный нейрон
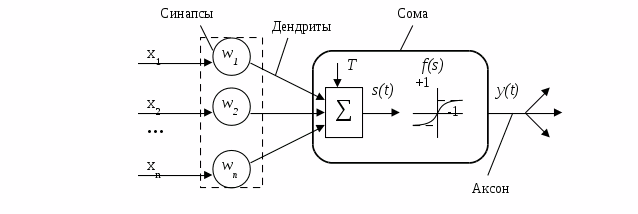
В 1943 году Маккалок и Питтс предложили свою математическую модель искусственного нейрона, являющаяся упрощённой моделью естественного нейрона. Математически, искусственный нейрон обычно представляют как некоторую нелинейную функцию от единственного аргумента — линейной комбинации всех входных сигналов. Данную функцию называют функцией активации или функцией срабатывания, передаточной функцией. Полученный результат посылается на единственный выход. Если проводить аналогию искусственного нейрона с биологическим, то синапсы это веса, дендриты передают информацию к телу нейрона (сумматору), а аксон это выход функции.
Перцептрон
Практически сеть была реализована Фрэнком Розенблаттом в 1958 году как компьютерная программа, а впоследствии как электронное устройство — перцептрон. Перцептрон состоит из трёх типов элементов, а именно: поступающие от сенсоров сигналы передаются ассоциативным элементам, а затем реагирующим элементам. Таким образом, перцептроны позволяют создать набор «ассоциаций» между входными стимулами и необходимой реакцией на выходе.
Первоначально нейрон мог оперировать только с сигналами логического нуля и логической единицы, поскольку был построен на основе биологического прототипа, который может пребывать только в двух состояниях — возбужденном или невозбужденном. Развитие нейронных сетей показало, что для расширения области их применения необходимо, чтобы нейрон мог работать не только с бинарными, но и с непрерывными (аналоговыми) сигналами. Такое обобщение модели нейрона было сделано Уидроу и Хоффом, которые предложили в качестве функции срабатывания нейрона использовать логистическую кривую.

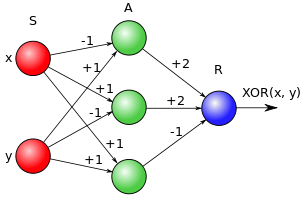
[!] Важно заметить, что есть тонкая грань между однослойной нейронной сетью, которая не может решить задачу XOR, и определением перцептрона, в котором А-слой не является входным слоем. В данном случай слой S-A, пусть даже и не обучаемый по определению, производит отображение S-слоя на ассоциативное поле A, таким образом переводя любую линейно неразделимую задачу в линейно разделимую. Интересно, что еще сам Розенблатт уточнял, что перцептрон без скрытых слоев не имеет смысла.
В итоге задачу XOR перцептрон легко решает:
Обучение перцептрона
Метод коррекции ошибки — метод обучения перцептрона, предложенный Фрэнком Розенблаттом. Представляет собой такой метод обучения, при котором вес связи не изменяется до тех пор, пока текущая реакция перцептрона остается правильной. При появлении неправильной реакции вес изменяется на единицу, а знак (+/-) определяется противоположным от знака ошибки.
Критика перцептрона
В последствии в 1969 году Минским и Папертом была написана книга, критикующая возможности перцептрона.
В основном были выделены следующие ограничения:
- Неинвариантность относительно переноса, вращения или растяжения
- Нет преимуществ относительно других статистических методов в прогнозировании
- Ограничение по скорости и памяти
Многослойный перцептрон
Чтобы не возникало путаницы, в данный момент под многослойным перцептроном понимают частный случай перцептрона Розенблатта - многослойный перцептрон Румельхарта. В нем обучаются все слои методом обратного распространения ошибки.
Дальнейшее развитие
После критики перцептрона область ИИ начала угасать. Даже алгоритм обратного распространения ошибки, появившийся в 1974 году, с помощью которого можно эффективно обучать многослойный перцептрон, не сильно повлиял на дальнейшую популярность нейронных сетей.
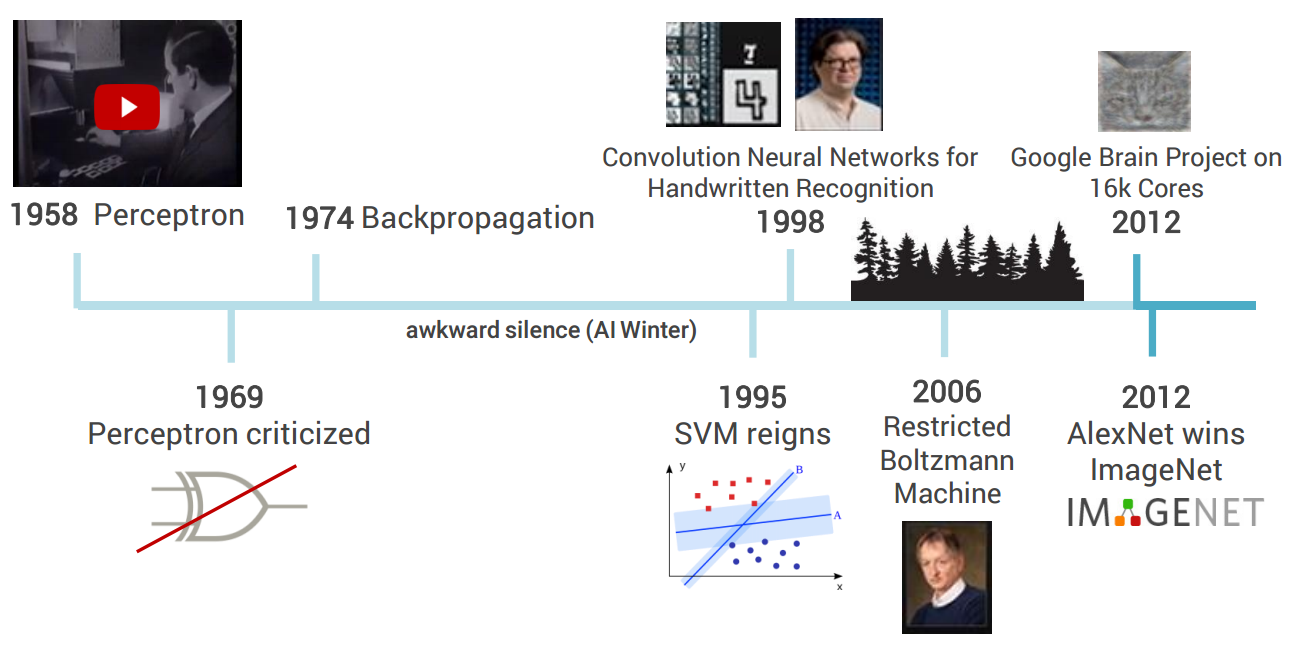
В начале 90-х ситуация резко поменялась. В то время компьютеры уже обладали нужными мощностями, аналитики владели большим объёмом данных, а математики придумывали новые алгоритмы для того, чтобы компьютер смог обучать себя сам на основе определенной модели. Тогда вместо экспертных систем, которые были четко запрограммированы, начали использовать вероятностный подход. В таком случае все неопределенности, которые могли быть в параметрах, уже были включены в модель.
Данный подход называется машинным обучением (Machine Learning). В нем интеллектуальные системы приобретают свои собственные знания, путем извлечения некоторых шаблонов из предложенных данных.
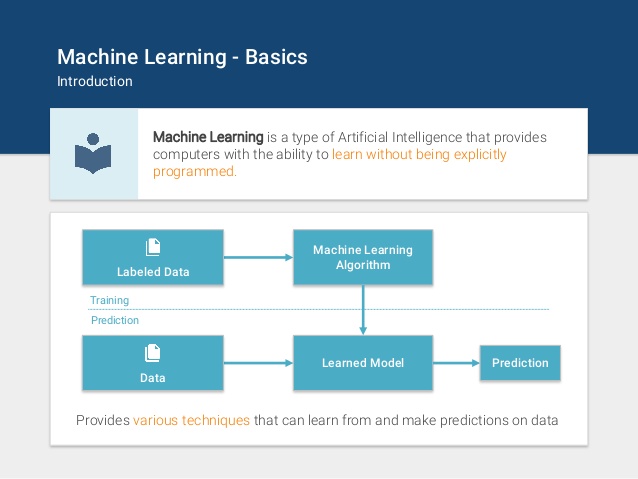
Начиная с этого момента все начинает полностью зависить от того, как мы представим данные для алгоритма самообучения. Допустим мы работаем в банке и хотим решить, давать ли кредит тому или иному человеку. У нас о нем есть много информации, которую мы можем использовать и скормить алгоритму, но сильно ли повлияет рост человека на его платежную способность? Поэтому нужно тщательно отбирать особенности (признаки, features), которые влияют на конечный результат. В этом и заключается основная особенность машинного обучения.
(!! бред какойто)В данный момент момент множество алгоритмов машинного обучения являются очень эффективными и используются везде, где только можно. Также популярным стало глубокое обучение, где слоев скрытых слоев больше чем один. В нем одно представление данных выражено через более простые представлления (в зарубежной литературе есть термин representation learning).